Fundamental concepts you should know while working with Elasticsearch

I am a problem solver and loves to learn the new languages, likes to connect with people and share amazing ideas; )
Elasticsearch is one of the important part of the ELK stack, E in ELK stands for Elasticsearch. When I initially started working with Elasticsearch I was bit overwhelmed with all the concepts. So I thought I should collect all the fundamental concepts which you should understand before starting working with Elasticsearch. Once you get the basics you can use it as per your requirements so let's dive into the concepts.
What is Elasticsearch?
As per Official documentation:
Elasticsearch is the distributed search and analytics engine at the heart of the Elastic Stack.
Elasticsearch provides near real-time search and analytics for all types of data. Whether you have structured or unstructured text, numerical data, or geospatial data, Elasticsearch can efficiently store and index it in a way that supports fast searches.
Some of the common use cases of Elastic search:
- Add a search box to an app or website
- Store and analyze logs, metrics, and security event data
- Use machine learning to automatically model the behavior of your data in real time
- Automate business workflows using Elasticsearch as a storage engine
- Manage, integrate, and analyze spatial information using Elasticsearch as a geographic information system (GIS)
- Store and process genetic data using Elasticsearch as a bioinformatics research tool
Basic architecture of elasticsearch
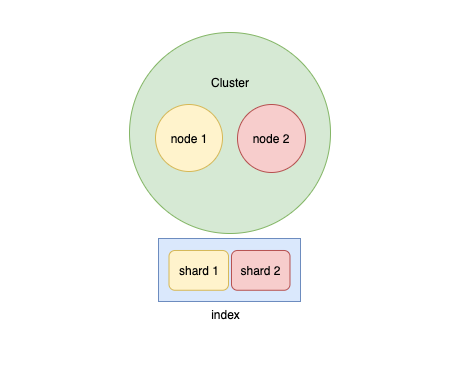
The above diagram consists of all the basic components in the elasticsearch. Let's take look at them one by one:
Document:
It is JSON object containing the data fields in form of key value pairs, it is basic unit of storage in elastic search
Every document is stored within an index. Below is the example of document with index name students:
{
"_id": "yerjfqkb45djkberg",
“_type”:"_doc",
“_index”: “students”,
"_source":{
"age": 18,
"name": "Daniel”,
"stream":"science",
}
In above example you can see that the actual data fields are present inside "_source", “_index” is the index name in which your document is stored and "_id" is the unique identifier for each document. Now let's see what is index.
Index:
Index contains collection of documents with similar characteristics and are logically related.
We can have as many indices defined in Elasticsearch as per our requirement. These in turn will hold documents that are unique to each index. In earlier example you can see that our index name is "students", so that will contain all the documents related to students, similarly we can have separate index for "teachers". Likewise we can separate the documents logically.
We can divide the index into shards for scalability.
Note: Concepts of shards and scalability will be explained in the next section.
Sharding and scalability:
Sharding is a way to divide indices into smaller pieces
Each piece is referred to as a shard
The main purpose is to horizontally scale the data volume
There is no limitation on placement of shards on nodes provided there should be enough space available in that particular node. -Default number of shards in index is one, where the elasticsearch version >7.0.0, you can specify the number of shards and it's replicas as shown in below example while creating the index:
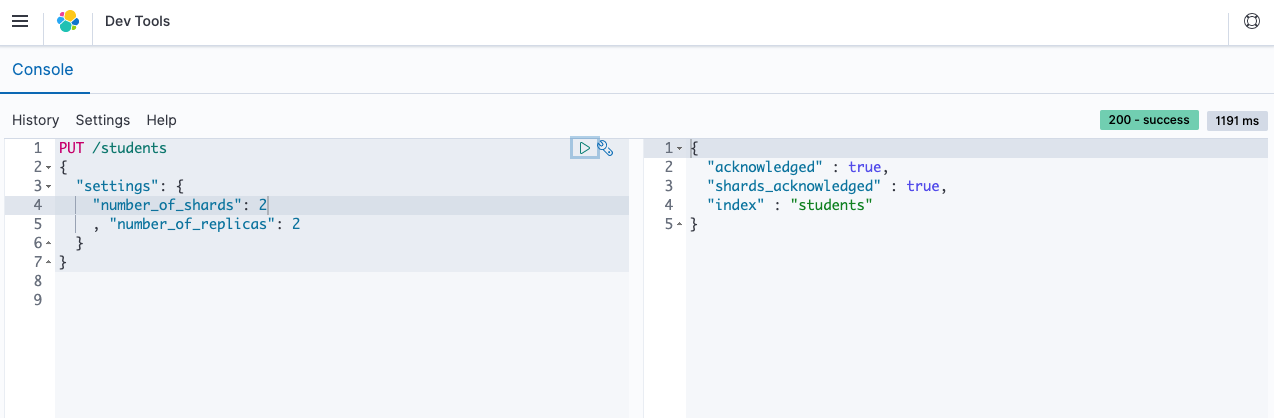
I have used elastic cloud to run this query in above image. You can see we have created two shards and two replicas.
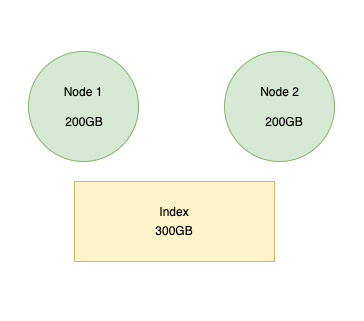
Consider below scenario where the index is of size 300GB, and the two available nodes have 200 GB space each, now we will not be able to store the complete data in single shard, so what can we do here?
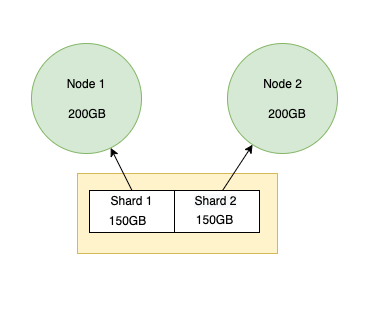
We can split the index into two shards with 150 GB memory each, this way we will be able overcome the space issue as shown in below image:
Nodes:
Any time that you start an instance of Elasticsearch, you are starting a node.
A collection of connected nodes is called a cluster. If you are running a single node of Elasticsearch, then you have a cluster of one node.
Every node in the cluster can handle HTTP and transport traffic by default. The transport layer is used exclusively for communication between nodes; the HTTP layer is used by REST clients.
There are many different roles present for nodes as defined below. Each node will behave differently based on the role assigned to it. If you don’t set node.roles, the node is assigned the following roles:
- master
- data
- data_content
- data_hot
- data_warm
- data_cold
- data_frozen
- ingest
- ml
- remote_cluster_client
- transform For more information on how to attach the roles to nodes and what is the importance of each role then refer official documentation
Cluster
- Elasticsearch cluster is a group of one or more Elasticsearch nodes instances that are related. You can also see the same in architecture diagram described in the starting of the article.
- Though the cluster can contain multiple nodes but that is not mandatory, we can create cluster with single node as well.
- We can get the information related to cluster and nodes with the help of cluster APIs
Replica
As the name suggests the replicas are replication of the data stored in the shard.
It is useful when any node with primary shard fails and elasticsearch is able to make replica shard as primary shard to avoid data loss. For this reason replica shards are always stored on different node than the primary one.
Like with shards, the number of replicas can be defined per index when the index is created.
Mapping and Analyzers:
Mapping and Analyzers are one of the important concepts which you will surely encounter while working with Elasticsearch
Mapping
- Mapping is the process of defining how a document, and the fields it contains, are stored and indexed.
- Each document is a collection of fields, which each have their own data type.
There are two types of mapping explicit mapping and dynamic mapping
Explicit mapping : allows you to precisely choose how to define the mapping definition, such as:
- Which string fields should be treated as full text fields
- Which fields contain numbers, dates, or geolocations,
- The format of date values,
- Custom rules to control the mapping for dynamically added fields.
Below is the example of explicit mapping while creating an index:
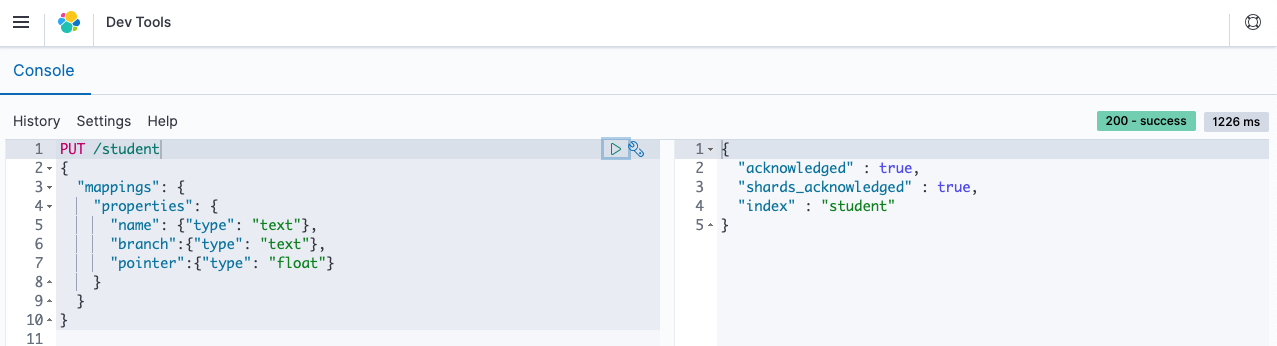
- Dynamic mapping : Elasticsearch generates mapping for us depending on the entered value for field dynamically.
Analyzer:
Analyzers are used in case of text fields, text values are analyzed while indexing documents.
When we store any document in the Elasticsearch at that time the fields are processed and results are stored into suitable data structure before storing them into an index so that it will be easier to get the results of any search query. And in case of text fields analyzers help in processing the results as per our requirement.
- Elasticsearch ships with a wide range of built-in analyzers, which can be used in any index without further configuration:
Standard Analyzer
The standard analyzer divides text into terms on word boundaries, as defined by the Unicode Text Segmentation algorithm. It removes most punctuation, lowercases terms, and supports removing stop words.
Simple Analyzer
The simple analyzer divides text into terms whenever it encounters a character which is not a letter. It lowercases all terms.
Whitespace Analyzer
The whitespace analyzer divides text into terms whenever it encounters any whitespace character. It does not lowercase terms.
Stop Analyzer
The stop analyzer is like the simple analyzer, but also supports removal of stop words.
Keyword Analyzer
The keyword analyzer is a “noop” analyzer that accepts whatever text it is given and outputs the exact same text as a single term.
Pattern Analyzer
The pattern analyzer uses a regular expression to split the text into terms. It supports lower-casing and stop words.
Language Analyzers
Elasticsearch provides many language-specific analyzers like english or french.
Fingerprint Analyzer
The fingerprint analyzer is a specialist analyzer which creates a fingerprint which can be used for duplicate detection.
- If you do not find an analyzer suitable for your needs, you can create a custom analyzer which combines the appropriate character filters, tokenizer, and token filters. Refer the below diagram to understand the inside structure of analyzer.
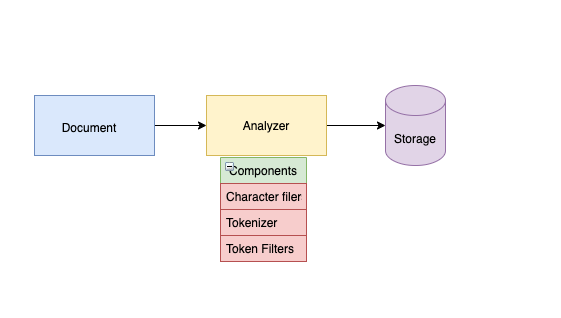
- Analyzer has three main components:
Character filter
Character filters are used to preprocess the stream of characters before it is passed to the tokenizer. For more information on what all Character filters are available please refer the link
Tokenizer
A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens. For instance, a whitespace tokenizer breaks text into tokens whenever it sees any whitespace. It would convert the text "Quick brown fox!" into the terms [Quick, brown, fox!]. For more information on tokenizer please refer the link
Token filter
Token filters accept a stream of tokens from a tokenizer and can modify tokens (eg lowercasing), delete tokens (eg remove stopwords) or add tokens (eg synonyms).
- These analyzed values for text fields are stored within an inverted index
- Each text field has dedicated inverted index
- Inverted index is mapping between terms and documents which contain them, if you want to get more information on this then please refer link
Conclusion
I hope you guys are now well equipped to start the journey with Elasticsearch. The main motto of this article was to introduce you all to the fundamental concepts of Elasticsearch, so that your further journey with it will be smooth. If you liked this article and found it useful then do share it with your friends, family and colleagues.




